Introduction
If you can't use snapshot technology to backup your web site, or would like something more flexible, then you'll need an automated process that creates an archive of your data and copies it somewhere safe. Simpler options are available! If you want to see what's involved, read on.
Incidentally, there is a Ghost export facility that lets you download your important configuration and textual data, and also an experimental API that should make automation possible, however, in this post we are going old skool and will be using a bash script to do the backup and standard linux facilities to automate the backup jobs.
Backup script overview
I've used this script on Ubuntu 20.04 and 22.04 and, although it will probably work on other modern linux distributions, I haven't tested it on anything other than Ubuntu.
As mentioned in other posts, I do this kind of thing for my own amusement and the script is offered without any kind of warranty or support:
 nickabs
nickabsIf you would like to use or modify the script you can retreive a copy from github:
git clone https://github.com/nickabs/lightsail-utils.git
>Cloning into 'lightsail-utils'...
>remote: Enumerating objects: 164, done.
>remote: Counting objects: 100% (31/31), done.
>remote: Compressing objects: 100% (15/15), done.
>remote: Total 164 (delta 23), reused 20 (delta 16), pack-reused 133
>Receiving objects: 100% (164/164), 47.43 KiB | 747.00 KiB/s, done.
>Resolving deltas: 100% (101/101), done.
cd lightsail-utils
ls
>LICENSE.md README.md ghost-backup.sh* lightsail-snapshot.shThe script will create archives of the Ghost database, content and configuration files and optionally copy the archives to Google Drive and send email confirmations:
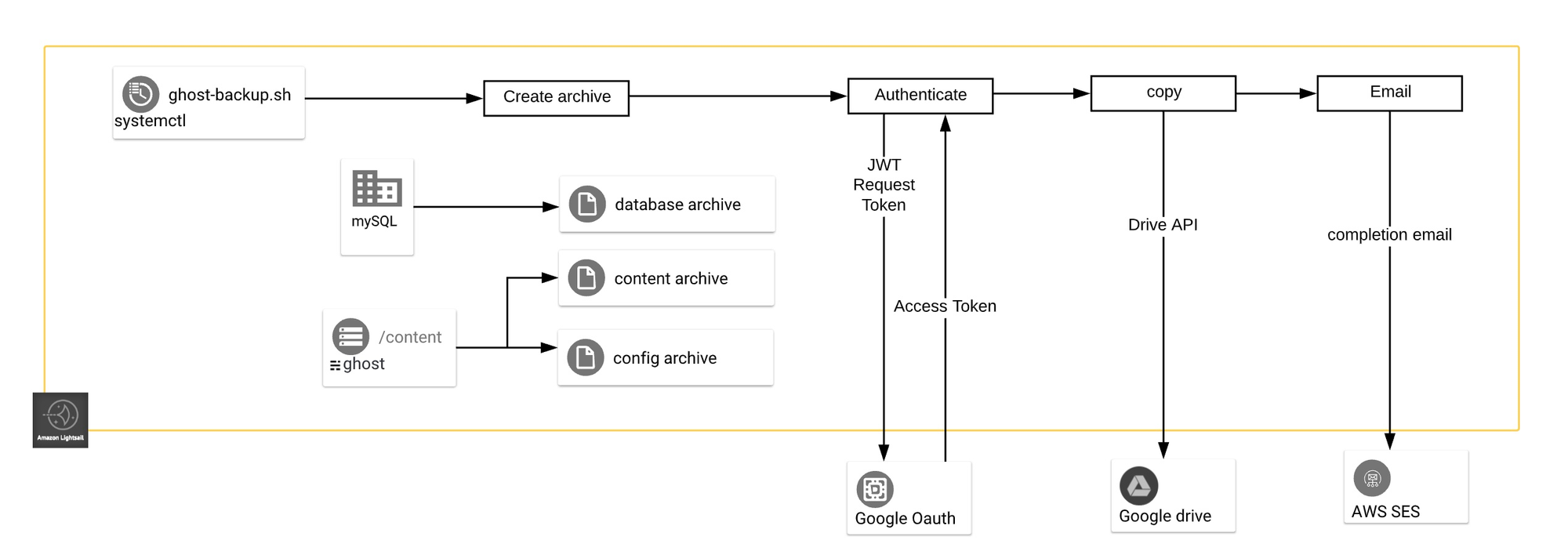
ghost-backup.sh overview
See the Usage section below for a description of the script options
Dependencies
The script uses various linux utilities (curl, gawk, gzip etc) that should be available on most linux distributions. The following may require additional package installations:
- There is an option to send an email when the script completes or in the case of an error. The email is sent using the aws command line interface.
- jq is used to parse Ghost configuration file and the json returned by the Google APIs. If jq is not available for your distribution you can find installation instructions on the github project
- There is an option to encrypt the archives and this uses gpg
These dependencies are discussed below.
Configuration archive
When you install Ghost using the recommended ghost-cli method a configuration file called config.production.json is created in the installation directory, for instance: /var/www/ghost/config.production.json.
This file contains important configuration information for the site and is backed up by the script. Note that the file contains your database password in plain text. See the Encryption section below if you plan to keep your database archives remotely.
Database archive
A standard Ghost installation stores user data in two places:
- Post, pages, tags, member details and site settings are held in a relational database
- all other data, including images and videos, and the files associated with themes are held in a content directory on the local filesystem of the server.
Production installations of Ghost uses MySQL[1] a venerable but elderly open source relational database. There are various proper "enterprise" backup solutions for MySQL, but for a small blog site we can get away with using the mysqldump utility that comes with the database server.
The programme output consists of CREATE statements to create dumped objects (databases, tables, users etc), and INSERT statements to load data into tables.
The database connection details are read from the database.connection object in the config.production.json configuration file located in the Ghost installation directory.
Content Archive
All locally stored user data accessible by Ghost is stored in the location specified in the contentPath object in the server configuration file config.production.json
The default location is a /content subdirectory under the installation directory, for example on my server the location is /var/www/ghost/content.
The script will create a compressed tar archive of this directory using relative paths, like this:
./images
./images/2020
./images/2020/01
./images/2020/01/wood.jpg
...
The script will not work if you use a ghost storage adapter to store your image data remotely.
Encryption
Note that the backup archives contain account credentials:
- the ghost config file (config.production.json) contains database access credentials in plain text.
- the database dump contains the
usertable and this holds hashed passwords and email addresses for staff members on the Ghost site.
There is an option to encrypt the config and database archives if you are going to keep them in a remote location. To use this option you must supply a passphrase at runtime and will need to supply the same passphrase when using the restore option.
You can use the gpg command to decrypt the files manually:
gpg --decrypt --passphrase your_pasphrase --batch "2021-12-06-archive.gz.gpg" > "2021-12-06-archive.gz"Housekeeping
The script creates three gzip archives and places them in a directory specified at runtime. The files for each daily archive are stored in a subdirectory named YYYY-YY-DD that is created by the script:
2021-02-19/2021-02-19-database.sql.gz # mysql database dump
2021-02-19/2021-02-19-content.tar.gz # content (themses, images etc)
2021-02-10/2021-02-19-config.gz # Ghost config file
The script deletes the oldest daily archive directories up to the maximum number of retained snapshots specified at runtime.
Email notifications
Optionally the script can send an email message showing the status of the backup job after it completes.
The script uses the AWS Simple Email Service (SES) to send the mail. If your server is installed on Amazon EC2 then you can send 200 SES emails per day from your EC2 instances at no charge. This Free Usage Tier benefit does not expire:
AWS Lightsail instances are actually just rebadged EC2 instances so happily they too qualify for the free SES tier.
The instructions to set up SES are here:

As part of the set-up process you need to verify that you own the "From" and "To" email addresses and the domain the message is being sent from. You will need to add some records to your DNS to do this. For more information, see Verifying identities in Amazon SES.
The script uses the aws command line interface (cli) to send the message.
You will need an AWS account with ses:SendEmail permission. This account can be used to generate an access key that should be installed as an aws cli named profile. The aws cli then uses the profile to authenticate with AWS SES.
Scheduling
In the olden days we used to schedule regular jobs using cron but no more, as today we can use systemd timers. They are a bit more of a faff to set up, but the logging & monitoring features are big improvements. I was also pleased to discover a command you can use to check your timings
systemd-analyze calendar "*-*-* 01:10:00"
>Normalized form: *-*-* 01:10:00
> Next elapse: Mon 2021-12-20 01:10:00 UTC
> From now: 11h leftThese instructions work on Ubuntu 20.04 and the directories might need tweaking on other distributions (assuming they support systemd).
- create a service unit file:
/etc/systemd/system/ghost-backup.service:
[Unit]
Description=Service for ghost-backup.sh script
[Service]
EnvironmentFile=-/etc/environment
ExecStart=/bin/bash /usr/bin/ghost-backup.sh -w /var/www/ghost -l /var/log/ghost-backup/ghost-backup.log -b /var/www/ghost-backup -m14
SyslogIdentifier=ghost-backup
Restart=no
WorkingDirectory=/tmp
TimeoutStopSec=30
Type=oneshot
2. create a timer unit file: /etc/systemd/system/ghost-backup.timer
[Unit]
Description=Timer for ghost-backup.sh
[Timer]
#Run on Sunday at 22:10am
OnCalendar=*-*-* 01:10:00
Persistent=true
[Install]
WantedBy=timers.target
The timer is associated with the timers target (this target sets up all timers that should be active after boot).
3. prepare the timer
sudo systemctl enable ghost-backup.timer
>Created symlink /etc/systemd/system/timers.target.wants/ghost-backup.timer → /etc/systemd/system/ghost-backup.timer.
sudo systemctl start ghost-backup.timer
the enable command configures the system to start the ghost-backup.timer unit automatically at boot time by creating a symbolic link from the timer unit file to the appropriate directory for system startup. The start command activates the timer.
4. test the service runs
you can directly run the service using this command:
sudo systemctl start ghost-backup.service5. check status:
systemctl status ghost-backup.timer
>● ghost-backup.timer - Timer for ghost-backup.sh
> Loaded: loaded (/etc/systemd/system/ghost-backup.timer; enabled; vendor preset: enabled)
> Active: active (waiting) since Thu 2022-12-08 07:50:16 UTC; 1 day 2h ago
> Trigger: Sat 2022-12-10 01:10:00 UTC; 14h left
> Triggers: ● ghost-backup.service
systemctl status ghost-backup.service
>○ ghost-backup.service - Service for ghost-backup.sh script
> Loaded: loaded (/etc/systemd/system/ghost-backup.service; static)
> Active: inactive (dead) since Fri 2022-12-09 01:14:21 UTC; 9h ago
>TriggeredBy: ● ghost-backup.timer
> Main PID: 8008 (code=exited, status=0/SUCCESS)
> CPU: 2min 22.624s
>
>Dec 09 01:13:21 ip-172-26-8-33 ghost-backup[8008]: LOG: 4.26 GiB available, future space needed estimated to be 2.69 GiB
>Dec 09 01:13:22 ip-172-26-8-33 ghost-backup[8008]: LOG: backup dir created, name="2022-12-09", id="1KAuHGpA7a1MzUofSoWFcPWJP5DgDMe>6. enable log rotation: /etc/logrotate.d/ghost-backup
/var/log/ghost-backup/*.log {
rotate 14
weekly
missingok
}
Remote storage (Google Drive)
By default the script will maintain the backup archives in the local filesystem directory that you specify at runtime. However, you shouldn't really keep backups on the local file system in case you lose the virtual machine (and your backup archives with it).
Virtual servers run on physical hardware which, like all hardware, can fail at any time. If you are using Lightsail to host your server then you are running what Amazon refer to as an EBS-backed instance. EBS, or Elastic Block Storage , provides you some protection from data loss caused by this type of failure, since the root device is an EBS volume that is stored independently[2] of the host machine. This means that, if the host machine fails, restarting the stopped instance will migrate it to new hardware.
Nonetheless it is good practice to keep your archives separately from your server, after all, just as it is possible to create new VMs at the click at the button, it is just as easy to accidentally delete them.
The remote storage option will upload the backup archives to Google Drive using a service account. Service account are created in the API section of the Google Developer Console and are identified by an email address e.g example@project-id.iam.gserviceaccount.com.
These accounts have their own storage quota on Google Drive (as of late 2021, the quota is 15 GiB).
There are some limitations to service accounts we need to be aware of:
- Service accounts can only access Google Drive files that they own
- The service account's Google Drive storage quota can't be increased
- Service accounts can't login via a browser
service account storage
The only way to manage a service account's Google Drive data is via the Drive API.
However, it is still possible to view the Google Drive service account data in your Google user account. To do this you must create a folder in Google Drive using your user account and then share the folder with the service account (you can then specify this shared folder id as a parameter to the script).
Note that if you use your own Google account to create files in one of the backup directories created by this script then it will no longer be able to remove the folder once it becomes older than the maximum retention date specified at runtime. This is because the Drive API checks that it has permission to delete all the files in the folder before executing the delete and, since the service account is only permitted to remove files it owns, it will not be able do this unless all files created by other users are removed first.
Similarly, the backup files can't be removed by your Google user account: deleting the file from the shared folder just removes the link to the original file owned by the service account.
As noted above you can't purchase additional Google Drive storage for a service account, so you are limited to storing as many daily backups as can be stored in the 15GiB storage allowed for these accounts. The script will produce a warning if the estimated storage requirements exceed the available space.
authentication
Service accounts are associated with private/public key pairs and these are used to authenticate to Google.
The private key can be generated in the API console and saved - along with other details about the account - as a Google JSON credentials file.
The credentials file must be stored on the machine where the script will run (the location of the file is specified at runtime).
authorisation
The service account email address and private key in the credentials file are used to authorise the account to access the Google Drive API using Oauth2.0.
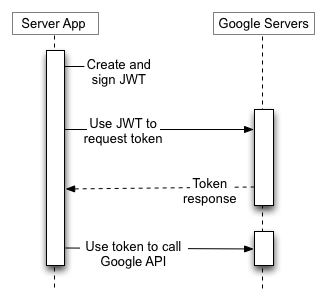
The backup script creates a JWT request token that is sent to Google's Oauth 2.0 service. Assuming Google can validate that the token was signed by the private key associated with the public key it holds for the account it will return an access token. The access token is valid for one hour and is used to access the resources requested in the scope specified in the original JWT access request (the backup script requests the scope needed to read/write to the service account's Google Drive storage).
Note the service account can also be used to access other Google Cloud Platform (GCP) services and you therefore need to specify (or create) a GCP IAM role when you create the account. It is good practice to limit access to the minimum set of resources needed by an account to do its work, however, since Google Drive is part of Google Workspace and not GCP, there are no IAM permissions that apply to the Google Drive API. There is no obvious way to prevent service accounts created solely for Google Drive access from also being used to access GCP services other than by creating a profile with an impossible to fulfil set of conditions.
Protecting your account
Although the service account can't access your personal user data, anyone in possession of the service account's private key can access all the GCP resources allowed by the profile assigned to it - potentially allowing them to rack up unwanted bills - and of course they will also be able to access your backups. You should learn about keeping your keys safe.
Usage
This command will backup a Ghost blog and retain a maximum of 7 daily archives on the server:
ghost-backup.sh -m archive -l ghost.log -a /data/archives/ghost -g /var/www/ghost -k7 -o allThe following command will backup a Ghost blog and copy the data to a Google Drive folder. A maximum of 7 daily archives will be kept in the remote storage. The script will send an email on completion:
ghost-backup.sh -m archive -l ghost.log -a /data/archives/ghost -g /var/www/ghost -k 7 -o all \
-r -G 1v3ab123_JZ1f_yGP9l6Fed89QSbtyw -C project123-f712345a860a.json \
-f ghost-backup@example.com -t example@mail.com -a LightsailSESAdmin
You can restore from an archive too. Take care as this action will overwrite the specified Ghost installation. For instance, this command will restore the database archive from the 1st of February 2021:
ghost-backup.sh -m restore -l ghost.log -g /var/www/ghost -l -a /data/archives/ghost -d 2022-02-01 -o allIf you want to restore all three archives use -o all. When using the restore option with the remote storage option the archive files will be retrieved from the specified google drive folder first. If you just want to retrieve the archives without restoring then use -d (download) instead of -R (restore)
The script options are described below:
| -m | specify the mode of operation (archive, retrieve, restore) |
| -a | The directory where the Ghost installation is installed |
| -l | log file name |
| -a | local directory for backup archives (used as a temp storage location when using the remote option) |
| -k | maximum daily backups to keep |
| -o | specify the archive options (config, database, content or all) |
| -r | use remote storage (copies the archives to Google drive) |
| -d | archive date (use when restoring or retreiving an archive) |
| -G | Google Drive folder id to store the backups |
| -C | Google service account credentials file |
| -f | from email (email sent on script completion) |
| -t | to email (email sent on script completion) |
| -A | aws SES profile name |
The next job is to sort out monitoring.
References
| 1⏎ | sqlite is used for development instances. There was apparently attempt to add support for Postgresql, but the maintainers abandoned it. |
| 2⏎ | Amazon EBS volume data is replicated across multiple servers to prevent the loss of data from the failure of any single component. |